I needed a way to detect UI blocks on screenshots without relying on expensive vision models. 50 experiments later, I found what works.
The Problem
Vision models charge per token. A single 4K screenshot can cost 36,000 tokens with GPT-4o-mini. I needed something cheaper for my automation pipeline.
The idea: use Tesseract OCR (free) to extract text, then algorithmically group words into meaningful blocks.
5 Algorithms Tested
| Method | Approach | Result |
|---|---|---|
| M1 Word Clustering | Group words by distance | Best for lists (Gmail) |
| M2 Whitespace | Find empty areas between content | Best for cards (BBC) |
| M3 Connected Components | Binary image + dilation | Merges everything |
| M4 Hierarchical | Regions first, then M1 | = M1, doesn't see images |
| M5 Image Detection | Variance analysis | Unreliable |
First Attempt: Column Detection
My first approach was simple: find vertical gaps in the text, split into columns.
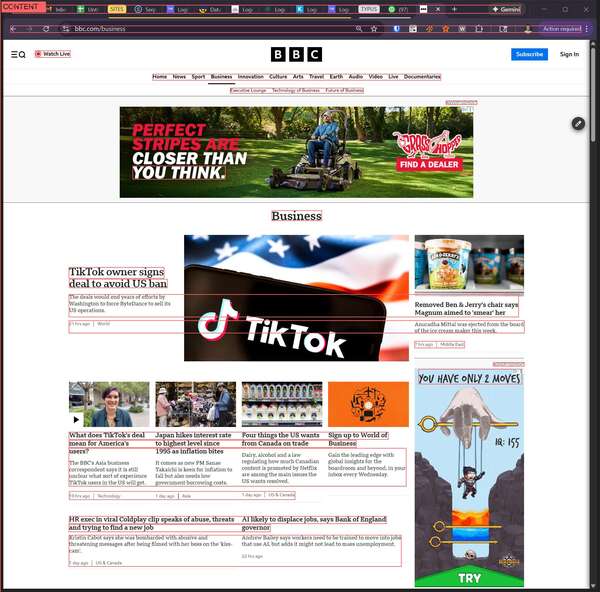
Result: useless. The algorithm sees vertical stripes, not content blocks. TikTok card, Epstein photo, sidebar - all mixed together in arbitrary columns.
The Winner: Hierarchy (M2 + M1)
Neither M1 nor M2 alone was perfect. The solution: combine them.
- M2 finds blocks - detects whitespace, everything between = block
- M1 finds elements inside - clusters text within each block
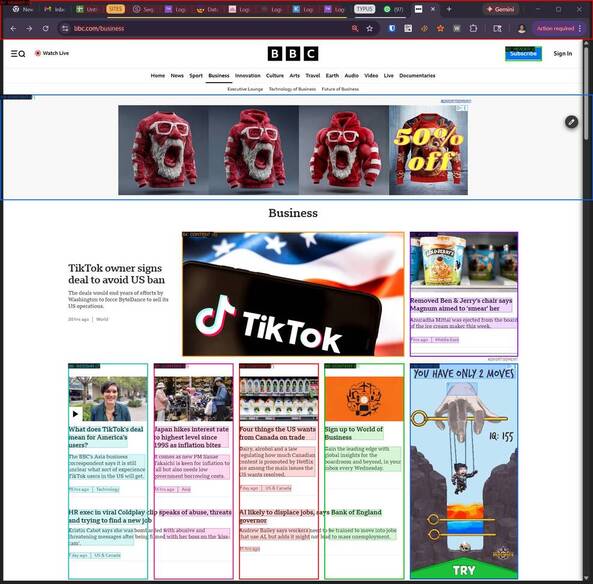
Result on BBC News: 11 blocks, 24 elements. Each news card is a separate block with clickable elements inside.
Key Parameters
y_th=40 # vertical merge threshold (lines -> paragraphs)
min_w=100 # minimum block width (removes narrow artifacts)
x_th=350 # horizontal merge (words -> lines)Gmail Test
Same algorithm on Gmail: sidebar and content are separate blocks. Each email is a distinct element.
- Block 1: Sidebar (Inbox, Starred, Sent...)
- Block 2: Email list (42 separate emails)
The API
GET /semantic?window=chrome&visualize=trueReturns:
{
"mode": "hierarchy",
"blocks": [
{
"name": "CONTENT",
"bounds": [x1, y1, x2, y2],
"elements": [
{"text": "TikTok owner signs deal...", "bounds": [...]}
]
}
],
"total_elements": 24
}Cost Comparison
| Approach | Cost per 1M requests |
|---|---|
| GPT-4o-mini vision | $5,551 |
| Tesseract + Algorithm | $0 |
The algorithm isn't as smart as GPT-4, but for structured UIs it's good enough - and infinitely cheaper.